本博客记录了如何使用百度开源深度学习框架PaddlePaddle实现了一个seq2seq模型,并侥幸获得“PaddlePaddle AI 产业应用赛——汽车大师问答摘要与推理”比赛一等奖的过程。
背景
一个偶然的机会,发现了一个AI比赛——PaddlePaddle AI 产业应用赛——汽车大师问答摘要与推理。这个比赛要求选手们使用汽车大师所提供的11万条技师与用户的多轮对话与诊断建议报告数据建立模型,从而可基于对话文本、用户问题、车型与车系,输出包含摘要与推断的报告文本,考验模型的归纳总结与推断能力。
看到这个比赛后,“多轮对话”数据第一时间吸引了我的注意,先申请参赛看看数据再说。 这个比赛基于科赛平台,完成注册后,可以在科赛为你提供的云端虚拟机环境中看到数据,但是没有办法把数据下载到本地,( ⊙ o ⊙ )! 这么狠,搞数据的想法破灭了,哭。
既然报名了,就尝试做一下吧,这毕竟是实际商业场景中产生的真实多轮对话数据。 数据产生的场景是这样的,一些车主在自己的爱车遇到问题时,在汽车大师App上发起提问,专业技师会根据问题(Problem)和用户进行一段对话(Conversation),从而帮助用户解决问题,最后技师根据问题和对话生成一个报告(Report)。 如下图所示。
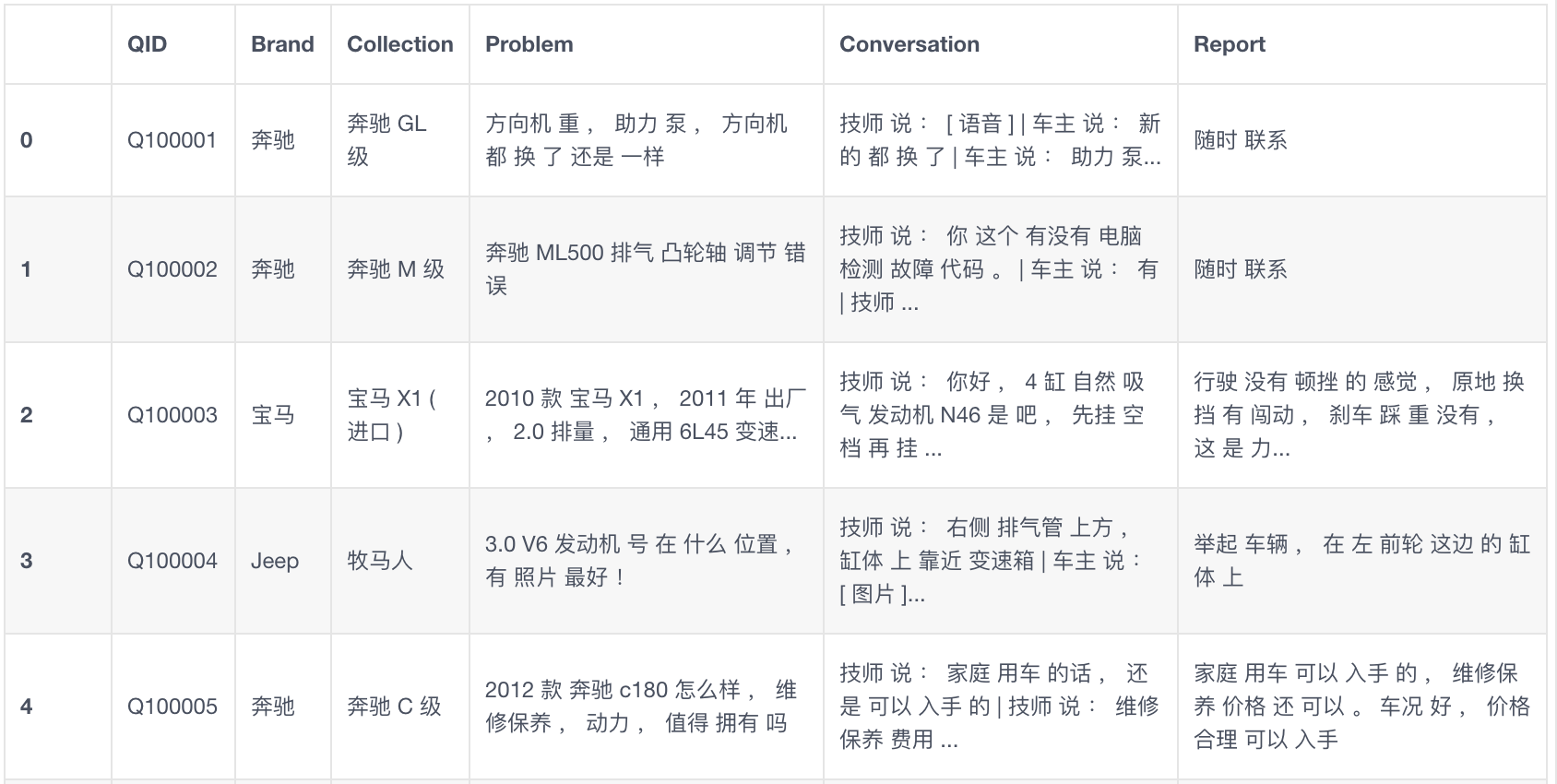
这个比赛的任务就是给定问题(Problem)和对话内容(Conversation),自动生成报告(Report), 通过计算算法生成的report和标准答案的ROUGE分数,评估算法的性能。 这个比赛的数据集由10万多条样本的训练集和各5000条样本的开发集和测试集组成。
思考
如何解决这个问题呢? 那么要把这个问题抽象一下, 有下面几个角度:
- 从Problem 和 Report的关系看, Report是要给出Problem的解答,所以这是个QA问题啊?
- 从Conversation 和 Report 的关系看, Report是对Conversation 内容的总结和提炼, 所以这是个文本摘要问题啊?
- 结合Problem, Conversation 和Report 一起看,好像是根据问题,从Conversation中提取答案的过程, 所以这是个阅读理解问题啊?
到底哪一种理解方式好呢? 我还真通过简单的验证方法进行了尝试:
角度1:QA问题
QA问题的一种解决办法是进行问题匹配, 面对一个问题q,从训练集中选择出最相似的问题q’, 然后把q’的答案a’作为答案返回。 为了简单验证一下, 我写了一个简单的baseline,基于tfidf 计算问题相似度,选择训练集中最相似问题的report作为答案返回。 提交! 一看结果排行榜, 得分14.5,排名倒数第二位, 不要太惨。。。 仔细思考了一下, 可能存在这种情况:虽然提出的问题很像,但是实际情况各有不同,需要通过对话进一步找到真正的问题所在,因此一点都不使用对话信息生成的report是好不到哪里去。
角度2: 摘要问题
摘要问题我之前没有实际做过啊,怎么快速明确这个思路好不好呢? 这里感谢Markus同学分享的开源项目, 这里他尝试了一个比较粗暴的摘要方式,直接把Conversation中技师说的第一句话作为结果返回(在自动摘要问题中,段落的第一句话通常是比较重要的话)。这个简单粗暴的方法得分是多少? 32.3286分, 我的天! 看来这个思路比QA要靠谱。
角度3: 阅读理解问题
如果看成是阅读理解问题, 那么就是从Conversation中找出能回答Problem的答案, 由于目前的阅读理解数据集的答案长度通常比较短(一般是几个单词),所以state of the art的作法是根据Problem,从Context中选择一段作为答案,模型只要输出答案的开始和结束位置即可。 但是这个任务的report有点长,常常出现几十个甚至上百个词, 而且report中的词好像并不完全是来自于Conversation。 我写了个程序统计了一下, Report中67.7%的词来自于Conversation, 这个比例虽然不低,但是还是让我放弃了从Conversation中选择一段作为Report的方法。
我的思路
我更想把这个问题看成是摘要问题, Report是Conversation的摘要,但是是由Problem指导的摘要。 所以我觉得设计一个seq2seq的网络结构, 根据Problem和Conversation, 以生成式(而非抽取式)的方法,生成Report。 在算法上,我很大程度参考了Teaching Machines to Read and Comprehend 这篇论文。
动手
在明确思路后,就要开始动手了, 这个比赛要求必须使用百度的PaddlePaddle框架,而大家对于这个框架的熟悉程度显然不如tensorflow, pytorch, keras等(我想这可能是我侥幸夺冠的主要原因(囧))。 由于我考虑使用seq2seq结构, 就以PaddlePaddle公开的机器翻译代码作为基础,实现了自己的模型。 由于代码是运行在科赛的平台上,而且是以notebook的方式运行,所以我的代码并没有整理成为结构分明的代码库,而是一个庞大的notebook。。。目前已经在科赛网上开源了, 感兴趣的同学可以看一下,其中包含了从预处理到训练到测试的完整流程,所以有点长。。。
值得提到的一些小的点是:
- 利用训练集、开发集和测试集中的文本预训练了词向量作为word embedding层的初值;
- Problem的encoder 和 Conversation 的encoder 共享了参数;
- 在attention decoder时, 引入了Problem 的 encoder结果计算attention score;
- Decoder softmax 层的参数矩阵和embedding层共享了参数, 这一点我感觉很重要。
结果
这个比赛分为初赛和复赛两个阶段。
初赛
初赛阶段只能使用科赛提供的CPU环境,而且环境时间只有三个小时,三个小时后得手动“续命”,否则程序就自动断掉了; 三个小时对于使用CPU训练seq2seq网络简直太短了。。。为此我削减了模型复杂度, embedding size和 GRU的hidden size都设为100, 三个小时可以勉强训练1.5个epoch, 如果忘了“续命”,程序被杀掉后,就只能载入最新的checkpoint继续训练, 同时手动调节学习率。 最终成绩勉强超过 “暴力选择第一句” baseline, 进入了复赛。当时看自己的排名感觉并没有什么戏,抱着随便搞搞的心态。
复赛
复赛阶段可以使用GPU环境, 环境时间变成了3天,真是鸟枪换炮,太爽了。 所以我直接增加了模型复杂度, 将embedding size和 GRU的hidden size增加到了256, 连续训练了5个epoch, 结果一提交, 我的天, 35.4分, 直接到达了当时的第一名! 我发现成绩不好的时候,动力是很足的,脑袋里思考着各种改进方法, 但是一下到第一之后,懒惰情绪立刻就上来了,各种改进方法就丢到脑后了…… 在训练过程中,我发现decoder在每个时刻预测出正确的词的概率只有50%左右,所以这应该是欠拟合啊, 那么应该继续增加模型复杂度吧。所以我干脆把embedding size和 GRU的hidden size又翻了一倍到512, 在训练了4个epoch开发集性能不再提升时手动降低了学习率又训练了一个epoch,就取得了我最终的最好成绩:36.26+。 这个成绩占据了一段时间的排行榜第一,让我继续松懈下去,最后被别人超过了。。。 被人超过之后,我垂死挣扎了一下,尝试把embedding size和 GRU的hidden size再翻了一倍到1024, 结果并没有效果。。。
不过,最终,由于我和第二名的分数差距不大, 另外可能我的提交报告写的比较好,总评我取得了第一名,汗。
心得
总结一下整个比赛过程,还是有一些想法的:
- 我认为绑定Decoder softmax 层的参数矩阵和embedding层的参数是有效果的,但是由于我代码写的有点问题,这个绑定限制了我的网络结构中embedding size和 GRU的 hidden size必须一致,导致我后面把hidden size增加到1024时,embedding size也必须到1024, 我感觉hidden size到1024还可以,甚至更大都行,但是embedding size到512就已经不小了, 实际可以在gru decode之后再加一层,从hidden size 降到embedding size之后, 再过绑定的softmax 就可以了, 当时没有做,可能有效果。
- 把GRU换成LSTM有可能还会好一点?
- 在摘要中使用CopyNet, Pointer network好像是比较有用的,特别在这个任务中, Report中有67+%的词是来自Conversation, 所以CopyNet, Pointer network应该会更好,但是由于对PaddlePaddle不太熟悉,不会实现这样的网络。。。
- 在用seq2seq产生自然语言时, 引入Reinforcement Learning通常是非常有效的,可以解决训练和测试目标不匹配的问题(训练是看每个时刻的分类误差, 而测试时是用ROUGE, BLEU之类的整句的评估算法), 但是同样没能实现。
- 这是我第一次使用PaddlePaddle, 使用的版本好像是paddle_v2 0.11, 总体来说PaddlePaddle使用还可以,实现基本功能的网络比较简单,参考样例代码就可以; 但是由于提供的api有些少,同时官方的文档相比tf和pytorch不够详尽,所以在想实现Pointer network 或者 Reinforcement Learning 等复杂些的网络和功能时就有些吃力。 PaddlePaddle 目前推出了Fluid版本,好像功能强大了不少,感兴趣的同学可以关注一下。
- PaddlePaddle我感觉最强大的功能就是处理文本数据的时候,在一个batch里可以支持边长的输入, 也就是说你完全不需要考虑paddling的问题, 我觉得这个对于做NLP任务的同学真的是太方便了。
PS:
- 虽然我的代码已经开源了,汽车大师的数据好像在科赛网上也能访问到,但是,按照科赛网提供的CPU环境+2小时限时,是没法正常完成训练的……
- 如果有想用PaddlePaddle做类似文本任务的同学,我在博客中介绍的零散思路和我的代码可能会有所帮助, 如果真能起到一点点的帮助作用,那么我写这期博客的目的就达到了90%。
- 毕竟还有10%的目的是想记录下自己第一个AI比赛冠军(*^__^*) 。