本博客记录了对“问题相似度计算”这个问题的初步探索尝试,分享了自己参加比赛:拍拍贷——第三届魔镜杯大赛的经历和一些心得,介绍了基于规则和基于深度学习两个角度的方法,希望对读者能有所启发。这个比赛参赛的选手很多,牛人也很多,笔者最终只取得了34名的成绩,刚刚进入前10%(共有350多只队伍提交了结果)。
背景
“问题相似度计算”这个问题,顾名思义,就是判断两个问题是否表达相同的含义,是NLP领域很重要的一个任务(虽然很重要,但是我之前从来没有实际接触过,囧)。早期在问答(QA)任务,特别是社区问答(CQA,比如百度知道、知乎等)中,这个任务非常重要,由于自然语言的灵活性,不同的人对于相同的问题可能使用不同的表述方式,那么对于某个用户提出的问题,可以使用“问题相似度计算”技术,和所有的已有问题进行计算,如果已有问题中存在某个问题和用户提出的问题意思是一样的,那么那个已有问题的答案就是用户需要的答案。
近年来,我们国家的服务业在不断发展,客服成了我们日常生活中经常打交道的对象,在客服场景中,“问题相似度计算”这个技术也是非常核心的技术,一方面这个技术是实现智能客服的基础,另一方面,这个技术也可以帮助人工客服实现用户问题和标准问题库中相似问题的快速匹配,从而为客户提供更好的服务。而我这次参加的比赛,就是在金融客服领域的“问题相似度计算”任务。 事实上,在魔镜杯大赛进行的同时,阿里也发布了一个“金融大脑-金融智能NLP服务”比赛,其任务也是“问题相似度计算”, 从这里也可以看出这个任务在实际商业场景中的重要性。
下面,我们就简单介绍一下魔镜杯比赛的基本情况。
任务
任务定义
魔镜杯比赛的任务非常明确,就是给定一个句子q1和另一个句子q2,系统自动判断这两个句子的含义是相同(label=1)还是不同(label=0)。
数据集
为了让选手可以训练问题相似度计算模型,魔镜杯发布了包含25万多个训练样本的训练集,每个训练样本由(label, q1, q2)组成。训练样本中的正例(label=1,也就是说两个句子含义相同) 和负例(label=0,两个句子含义不同)的数目分别是12万多和13万多,基本平衡。而魔镜杯发布的测试集包含17万多个样本,只给出了q1,q2,需要选手自动输出label。
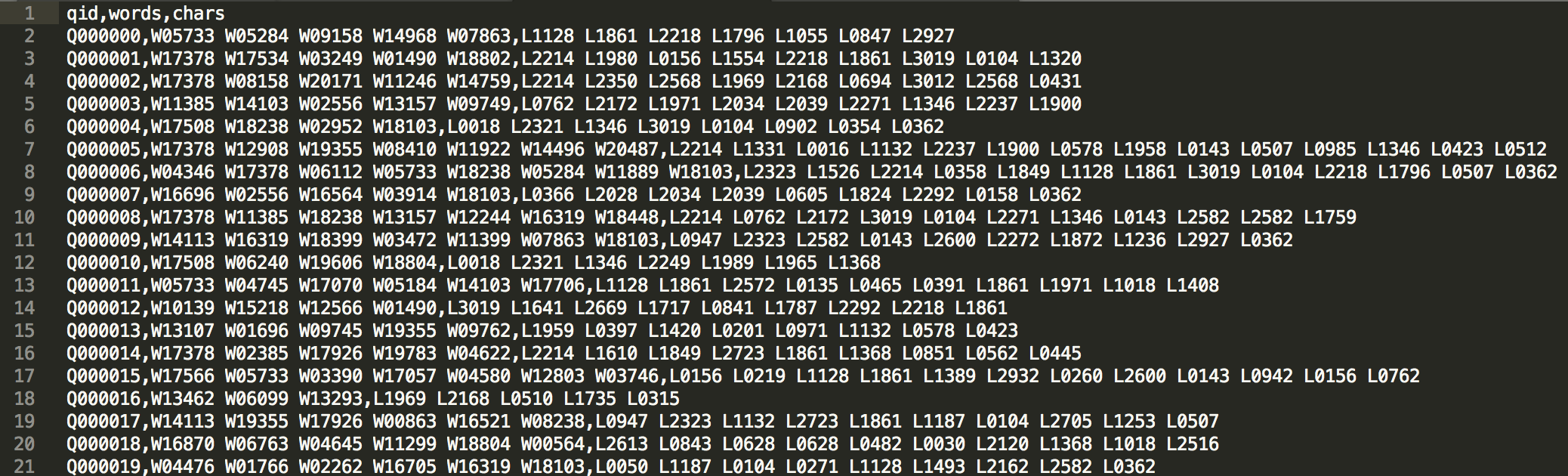
对于这种比赛,数据保护是主办方要考虑的一个问题,不同的比赛风格不同,比如我上一篇博客提到的汽车大师比赛,是利用虚拟化技术,数据放在云端上,无法下载到本地,因此也必须提供云端计算资源。而魔镜杯的方法我感觉非常有特色,那就是先把数据进行“加密”然后再公开,允许选手把数据下载到本地。下图 是魔镜杯发布的数据形式,训练集和测试集中的句子并不是以自然语言文本的形式给出的,而是给出了id化的词序列和字序列两种方式,词序列由词id组成,字序列由字id组成,无法直接看懂原句到底是什么。魔镜杯提供了2万个词左右的词典和3千个字左右的字典,并且提供了300维的词向量和300维的字向量。
思路
看到这个问题,我产生了两方面的思路,一是规则方法,二是机器学习方法。首先来看规则方法:
规则方法
本文所谓规则方法,是指不利用统计学习方法,而仅利用“含义相同”和“含义不同”这两种关系的特点进行推理的方法。
“含义相同” 和 “含义不同” 在本任务中都属于二元关系,可以作用于两个问题实例q1和q2,构成一个三元组(q1, r, q2),这里指定r1表示“含义相同”,r0表示“含义不同”。下面我们可以讨论下r1和r0的性质。
- 性质1: r1和r0都有对称性:即 (q1,r1,q2) 可以导出 (q2,r1,q1),缩写为 (q1,r1,q2) => (q2,r1,q1); 同样, (q1,r0,q2) => (q2,r0,q1)。 这个很好理解。
- 性质2: r1有传递性: (q1,r1,q2) and (q2,r1,q3) => (q1,r1,q3),这个也很好理解,如果q1和q2含义相同,q2和q3含义相同,那么q1和q3含义也相同,事实上这时q1,q2,q3构成了一个同义集, 集合中任意两个问句的含义都相同。
- 性质3: r0有特殊的传递性(不知道这个性质较叫什么): (q1,r1,q2) and (q2,r0,q3) => (q1,r0,q3),解释一下,如果q1和q2含义相同,但是q2和q3含义不同,那么q1和q3的含义也就不同,其实也很容易理解。
好了,在明确了r1和r0的特殊性质后,我们可以利用其性质,进行“关系补全”。训练集实际上提供了许多问题实例以及这些实例之间的关系,利用上述的性质2和性质3,我们可以基于训练集给出的实例和部分实例之间的关系,补全更多的实例之间的关系,具体做法可以分为两步:
- 利用性质2,寻找同义集合:对于训练集中所有“含义相同”的训练样本,可以根据性质2,将问句聚合成为许多个同义集合,同义集合中任意两个问句的含义都相同;
- 利用性质3,寻找同义集合间的“含义不同关系”: 这个话说起来有些绕,但是其实也很好理解,举个例子。对于两个同义集合S1和S2,我们一开始不知道这两个集合之间的关系,如果在训练集中我们发现了一个样本(q1, r1, q2),并且q1属于S1,q2属于S2,那么根据性质2,我们可以导出S1和S2可以合并为一个大的同义集合;那么如果在训练集中我们发现了一个样本(q1, r0, q2),并且q1属于S1,q2属于S2,那么根据性质3,实际上S1和S2之间就存在“含义不同”的关系,对于S1中的任意一个问句q1’和S2中的任意一个问句q2’,都存在“含义不同的关系”:(q1’, r0, q2’)。
通过上述这两步,我们可以得到很多同义集合S1,S2,…, 同时还知道了一些同义集合之间存在“含义不同”关系。这时,对于测试集中的一个样本q1, q2,我们就可以利用上述信息,进行判断了:
|
|
这时可能会有同学说,哎,你这个规则方法不行啊,存在“我不知道”的情况呢,那确实,所以才需要基于统计学习的方法嘛。
在比赛中,我使用基于规则的方法对基于统计机器学习方法输出的结果进行修正,如果基于规则的方法知道答案,那就用规则方法的答案,否则就使用统计方法的答案。
通过统计,基于规则的方法可以处理测试集中 10.54% 的样本,这个比例不算低了吧。
机器学习方法
之前提到过,我并不是很熟悉这个任务, 碰巧前段时间看过FAIR的一篇利用SNLI数据集有监督地训练句子向量表示的论文”Supervised Learning of Universal Sentence Representations from Natural Language Inference Data“, 感觉任务比较类似,所以就以这个论文的方法为基础进行了尝试。
SNLI任务是判断两个句子间的语义关系的,比如蕴含(entailment)、矛盾(contradiction)、中性(neutral)。上述的论文使用的方法是这样,先使用encoder对两个句子进行编码,得到向量表示u,v, 然后将u,v, |u-v|, uv 这四个向量连起来,经过一个MLP网络,输出三分类。结果如*下图所示。
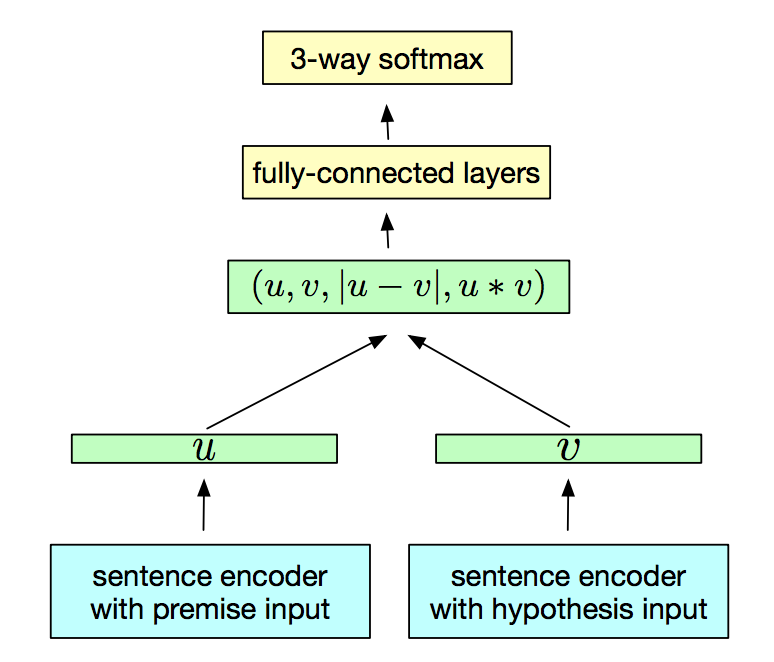
论文对比了多种encoder的效果, 包括:
- LSTM/GRU-last:使用LSTM或GRU对句子进行编码,然后选最后一个时刻的状态作为句向量表示, 可以单向也可以双向
- BiLSTM with mean/max pooling: 使用双向LSTM对句子进行编码,然后通过mean/max pooling 得到句子的定长向量表示
- Self Attention: 在BiLSTM的结果基础上,使用self-attention机制作为pooling方法得到句子的定长向量表示
- Hierarchical ConvNet: 使用深层(4层)CNN网络对句子进行编码, 然将每层经过max pooling后的定长向量连起来,作为句子的向量表示。
通过实验,该论文给出的结论是: BiLSTM + max pooling 效果最好。
这篇论文在GitHub上有官方的开源代码InferSent, 那么直接拿来用就好了。
在上述代码基础上,我做的工作有:
- 源代码使用GloVe (V1) or fastText 作为预训练的embedding,并且代码中并没有finetune embedding, 我尝试加入了finetune embedding,结果效果并不好;
- 由于这个网络结果对于q1和q2来说不是对称的,因此我在训练时会随机调整q1和q2的顺序;
- 在魔镜数据集上测试了各个encoder的性能,结果发现“BLSTMprojEncoder + max pooling” 效果最好,BLSTMprojEncoder的主要区别是加入了一个线性层将BiLSTM的状态进行了映射,然后再经过max/mean pooling;
- 对LSTM的层数设置进行了尝试,发现2层效果会更好,但是3层的效果会下降。
- 之前使用的都是基于词方法,我同时尝试了基于字的方法,发现效果差不多;
- 加入cross validation, 将训练集分成了10份, 以9份作为训练集, 1份作为开发集, 训练了10个模型, 然后ensemble。
代码
我的代码也公布在了GitHub上。
最终我的结果是三个模型ensemble的结果,这三个模型分别是:
- 2layer BLSTMprojEncoder + word feature + maxpooling + cv
- 1layer BLSTMprojEncoder + word feature + maxpooling + cv
- 1layer BLSTMprojEncoder + char feature + maxpooling + cv
当然最后的结果还使用规则系统的方法修正了一下。
心得
下面总结一下吧:
- 由于我的代码设计的有问题,只能要么使用word feature,要么使用char feature, 只能在ensemble时融合两种信息,可能在一个模型里融合这两种信息效果会更好;
- 另一个问题是由于对InferSent代码的修改非常少,只能用max pooling或者mean pooling,感觉如果max pooling和mean pooling的结果连接起来一起用可能会更好;
- 在调优时,我一开始使用SGD, 发现SGD对于不同的batch size效果不同,我扫描搜索了一下发现batch size不能太大,大概是128左右; 后来尝试了一下ADAM, 发现正好相反, ADAM对于大的batch size 效果比较好, 而小batch size 效果反而差。 这个结论不知道对于其他数据集或者任务是否适用。
- 可能有同学发现了,基于规则的方法实际上可以增加了训练样本,是的,但是由于我是利用业余时间随便搞搞,在最后一天草草尝试了一下数据扩充发现没有取得很好的效果,事后感觉应该早一点试试数据扩充的,可能能进一步提高结果。